不同于pipeline,parallelism需要额外的硬件资源
Instruction-Level Parallelism (ILP)
- Instruction-level parallelism: parallelism among instructions
- Pipelining is one type of ILP: because pipeline executes multiple instructions in parallel
- To increase ILP
- Deeper pipeline
- Less work per stage => shorter clock cycle
- Multiple issue (start multiple instructions in one clock)
- Replicate pipeline stages => multiple pipelines
- Start multiple instructions per clock cycle
- CPI (cycle per ins.)< 1, so use Instructions Per Cycle (IPC)
- E.g., for a 4GHz 4-way multiple-issue, peak rate is 16 BIPS (billion ins. per second), peak CPI = 0.25, peak IPC = 4, but dependencies reduce this in practice.
Two key responsibilities of multiple issue
- Packaging instructions into issue slots
- How many instructions can be issued
- Which instructions should be issued
- Dealing with data and control hazards
Multiple Issue
- Static multiple issue – decision made by compiler
- Compiler groups instructions to be issued together
- Packages them into “issue slots"
- Compiler detects and avoids hazards
- Dynamic multiple issue – decision made by processor
- CPU examines instruction stream and chooses instructions to issue each cycle
- Compiler can help by reordering instructions
- CPU resolves hazards using advanced techniques at runtime
Static Multiple Issue
- Compiler groups instructions into “issue packets”
- Group of instructions that can be issued on a single cycle
- Determined by pipeline resources required
- Think of an issue packet as a very long instruction
- Specifies multiple concurrent operations
- => Very Long Instruction Word (VLIW)
Dynamic Multiple Issue
- The decision is made by the processor during execution
- also called “Superscalar” processors
- CPU decides whether to issue 0, 1, 2, … each cycle
- Avoiding structural and data hazards
- No need for compiler scheduling
- Though it may still help
- Code semantics ensured by the CPU
Why need dynamic multiple issue
- Not all stalls are predicable
- cache misses
- Can’t always schedule around branches
- Branch outcome is dynamically determined
- Different implementations of an ISA have different latencies and hazards
MIPS with Static Dual Issue
Two-issue packets
- Divide instructions into two types: (Whether relates to memory)
- Type 1: ALU or branch instructions
- Type 2: load or store instructions
- In each cycle, execute a type1 and a type2 ins. simultaneously
- avoid data hazard
More instructions executing in parallel
EX data hazard
不能使用forwarding来避免两个packet中的指令引发的stall
- Forwarding avoided stalls with single-issue
- Now can’t use ALU result in load/store in same packet
Load-use hazard
- Still one cycle use latency, but now twoinstructions
More aggressive scheduling required
Improvement of multiple issue
Scheduling Static Multiple Issue
Compiler must remove some/all hazards
Reorder instructions into issue packets
No dependencies with a packet
Possibly some dependencies between packets
- Varies between ISAs; compiler must know!
Pad with nop if necessary

Loop Unrolling
- Replicate loop body to expose more parallelism
- Reduces loop-control overhead
- Use different registers per replication
- Called “register renaming”
- Avoid loop-carried “anti-dependencies”
- Store followed by a load of the same register
- Aka “name dependence” – Reuse of a register name

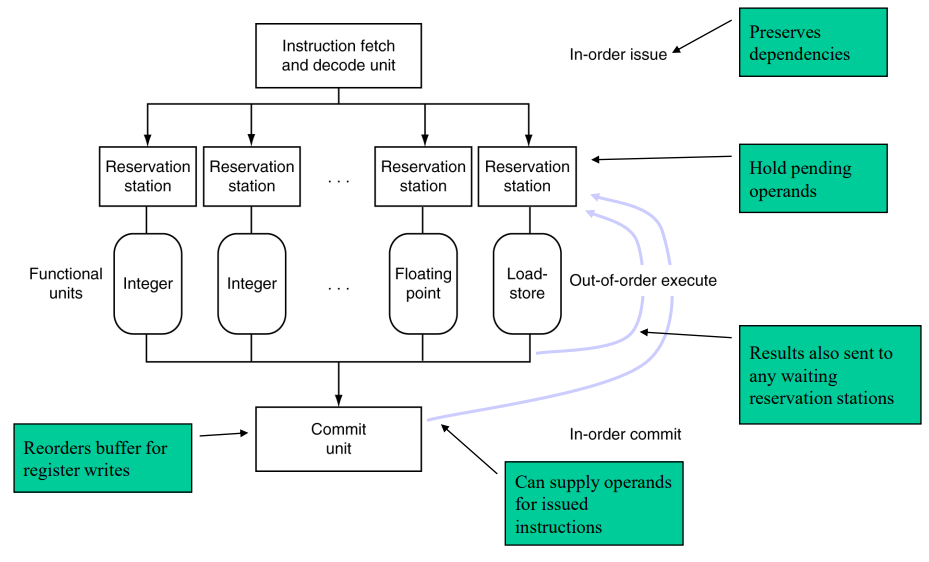
Dynamic Pipeline Scheduling
Hardware support for reordering the order of instruction execution
Allow the CPU to execute instructions out of order to avoid stalls
- But commit result to registers in order
Example
lw $t0, 20($s2)
addu $t1, $t0, $t2
sub $s4, $s4, $t3
slti $t5, $s4, 20
Can start sub while addu is waiting for lw
Speculation
- “Guess” what to do with an instruction
- Start operation as soon as possible
- Check whether guess was right
- If so, complete the operation
- If not, roll-back and do the right thing
- Common to static and dynamic multiple issue
- Examples:
- Speculate on branch outcome
- Roll back if path taken is different
- Speculate on load
- Roll back if location is updated
Compiler/Hardware Speculation
- Compiler can reorder instructions
- e.g., move load before branch
- Can include “fix-up” instructions to recover from incorrect guess
- Hardware can look ahead for instructions to execute
- Buffer results until it determines they are actually needed
- Flush buffers on incorrect speculation
Speculation and Exceptions
- What if exception occurs on a speculatively executed instruction?
- e.g., speculative load before null-pointer check
- Static speculation
- Can add ISA support for deferring exceptions 【汇编语言的exception】
- Dynamic speculation
- Can buffer exceptions until instruction completion (which may not occur)
Does Multiple Issue Work?
- Yes, but not as much as we’d like
- Programs have real dependencies that limit ILP
- Some dependencies are hard to eliminate
- e.g., pointer aliasing
- Some parallelism is hard to expose
- Limited window size during instruction issue
- Memory delays and limited bandwidth
- Hard to keep pipelines full
- Speculation can help if done well
Power Efficiency (Power Wall)
- Complexity of dynamic scheduling and speculations requires power
- Multiple simpler cores may be better
Fallacies
- Pipelining is easy (!)
- The basic idea is easy
- The devil is in the details
- e.g., detecting data hazards
- Pipelining is independent of technology
- So why haven’t we always done pipelining?
- More transistors make more advanced techniques feasible
- Pipeline-related ISA design needs to take account of technology trends
- e.g., predicated instructions
Pitfalls
- Poor ISA design can make pipelining harder
- e.g., complex instruction sets (VAX, IA-32)
- Significant overhead to make pipelining work
- IA-32 micro-op approach
- e.g., complex addressing modes
- Register update side effects, memory indirection
- e.g., delayed branches
- Advanced pipelines have long delay slots
Concluding Remarks
ISA influences design of datapath and control
Datapath and control influence design of ISA
Pipelining improves instruction throughput using parallelism
- More instructions completed per second
- Latency for each instruction not reduced
Hazards: structural, data, control
Multiple issue and dynamic scheduling (ILP)
- Dependencies limit achievable parallelism
- Complexity leads to the power wall